Hi, I'm Todd. I'm originally from near Preston, but I'm living and studying in Manchester at the moment. I'm super into Computer Science, which is why I'm studying it as a BSc. I'd like to say specifically what I like within CS, but unfortunately, the list is too long for a bio! Other than that, I'm sporty and love fantasy books.
I’m writing this post from Munich, where I am back at Google again for another Summer Internship, which also means that I’ve now completely finished my studies at the University of Manchester; I’m graduating in one month’s time!
It’s great to be back in Munich, I am with the same team at Google as last year, and it’s really great to see everybody again. Although I can’t talk about work things publicly, there have been some cool non-confidential changes since I left though; most notably a new (massive) office and the introduction of gBrau.
gBrau; Google’s exclusively brewed beer.
Once the Summer is over (and results pending), I will be going to study at Imperial College for a master’s degree. Preparing for that is taking up some of my spare time in Munich (sorting out the logistics such as accommodation and finances), but most of my time is free to explore southern Germany 🙂
Just this week, I also received my final degree results; I will be graduating next week with a first and am very pleased! So, that’s all from me. Blogging this year has been really fun, hopefully I will find a place (and the time) to carry it on in the future.
It’s the third and final week of the Easter holidays, which makes it a perfect time to write a blog post! I think Easter is my favourite holiday for two reasons. First of all, since it stretches out for a relatively long duration, it’s possible to take the time out to “recharge your batteries” and check off some less important bits and bobs of your todo list (for me, this is backing up all the family photos onto the cloud!). Secondly, time off at Easter isn’t spent inside the shadow of impending exams, so revision isn’t so urgent.
My family and I went to Durham for a few days which was a great break. It’s a quiet, quaint and hilly place, which is an ideal place to forget about all things university related for a while! The hotel we stayed at had a gym and a fantastic pool, so I despite going on a hiatus from work, I didn’t have to take a break form exercise too!
A view from a bridge over the River Wear. Durham Cathedral is on the right. The weather was quite cold, and the walk we were on was quite chilly!
Alas, all holidays have to end, and now it’s back to a mixture of coursework and dissertation writing. Thankfully, I’m working on a few cool things at the moment; in the AI & Games course, I’m implementing an AI to choose prices for goods to maximise the profit of a shop, in Introduction to Current Topics in Biology, I’m working on a short video describing how induced-pluripotent stem cells are being used to 3D print organs, and in Advanced Algorithms II, I’m working on implementing a program to solve systems of initial value problems (used to model things like chemical reactions and biological processes).
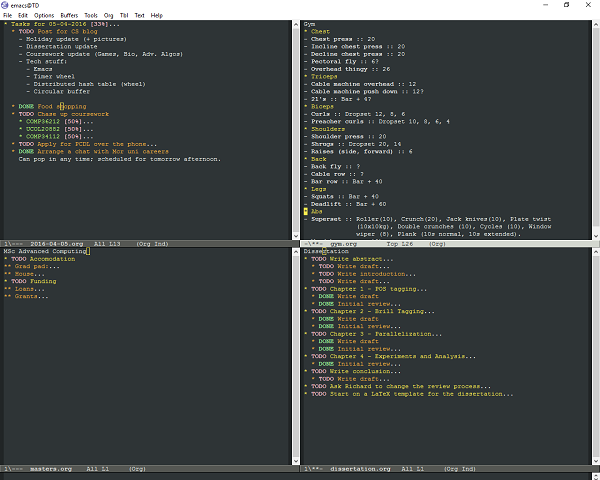
Outside of things strictly related to university work, I’ve begun the slow process of switching text editors from using Sublime to using Emacs. I had been tentatively using Vim for a while, but never really got over the super-steep learning curve that is learning the keyboard shortcuts. Emacs isn’t much better in terms of initial-usability, but the shortcuts make more sense to me, and I’ve been persuaded to give it a go by a number of blog posts (org-mode, emacs-latex) recently.
My current Emacs window; I’m using org-mode to work out what things need doing and keep track of other things. Right now, I’m using it to track where I’m up to writing my dissertation (keeping notes for each chapter), and to remind me what weights I’m lifting in the gym.
In my previous post, I said that I might talk about genetic algorithms in this post. However, I decided that if you want to learn about them, then you can take COMP36212. However, I came across two interesting blog posts with circle-related topics recently; one is about distributed hash tables (where the nodes in the hash table are arranged in a logical circle), and the other is about timing wheels (specifically approaches 4,5 and 6) which is a way to keep track of and fulfil timer requests (such as something like Thread.sleep() in Java). It’s not often that computer scientists get to use circular algorithms or datastructures in their work, in fact, we’re more likely to be actively avoiding situations where we have them (see cycle detection and circular dependencies).
However, circular buffers are an interesting topic I’d like to talk about. They solve the problem where you want to store some temporary data that you need to process but you only want to use so much memory to store the data.
A typical use case could be if you had something producing data such as a microphone, and something else consuming the data such as a voice processing app and you wanted to account for the situation where the voice processing app slowed down for some reason and couldn’t keep up with how much data was being produced by the microphone. In this situation, to avoid having to exceed your memory limits for the raw speech data, you need to either drop some old data from the buffer, or ignore some incoming data.
The first option is usually more useful, since old data is usually less important than new data, and this is the method implemented by a circular buffer. Wikipedia explains how a circular buffer works better than I would, but essentially, you have an array of data the same size as the amount of memory you want to use, and make the end of the array ‘wrap around’ to the start of the array if you try to add more data to the array than it can store, causing old entries to be overwritten by newer ones automatically if the buffer is full.
I got asked to implement a circular buffer in a coding interview once. I think it’s a good question, because the concept is easy enough for somebody who hasn’t met them before to grasp quickly, yet it’s easy to make silly mistakes such as off-by-one errors, so a candidate needs to work hard to convince themselves and the interviewer that their code works properly in all cases!
As I attempt to write a blog post while cooking a Pad Thai, I realise that this semester hasn’t gotten any less busy since my last update here; as my Grandma would say, “there’s no rest for the wicked”!
We had an unexpected surprise today in Manchester with the arrival of snow! Initially confused by our city’s initially pleasant but ultimately wet and slushy day, I’ve now come to the conclusion that the weather is getting revenge on my fellow blogger Veneta, who predicted Spring’s arrival in her last blog post.
It’s not just the snow which has been exciting recently; I received a confirmation of a place to study Advanced Computing at Imperial College London, and have just about finished finding (after looking for sooooo long) accommodation in Munich for the Summer, where I’ll be interning at Google again 😀
Furthermore, I’m putting the finishing touches to my final year project, which is now working and giving me the results that I expected! The project involves trying to speed up Text Mining algorithms (specifically training Brill’spart of speech tagging algorithm) using parallelization. To do this, I wrote single and multi-threaded implementations of the algorithms, as well as a version targeted for execution on a GPU in a massively parallel manner.
Here are some preliminary results from my project. The x-axis shows the number of operations performed, and the y-axis indicates how long it took to perform them all. Take a look at the light-green line, which is the single-threaded version of my implementation. Then look at the dark-green line; this is the version running on 512 GPU cores, it’s super fast!
Outside of my third year project, uni work is going super well! The courses I’ve taken this semester are so interesting that they sometimes border on addictive, especially Advanced Algorithms II and An Introduction to Current Topics in Biology. It’s miles easier to apply yourself and do work if you enjoy what you’re doing.
So, as you can see, it’s been a successful few weeks since I last posted. Now I need to start writing my dissertation! I decided not to include any heavy CS-stuff in this post, but I intend to write about genetic algorithms in the next one, so stay tuned!
This semester is proving to be rather hectic; I’m taking two extra modules compared to last semester, I’ve also got my dissertation to write and my project to finish. However, having lots of work doesn’t mean boring days of endless compiler theory, stackelberg games and floating point error analysis.
A combination of new years resolutions and scary blog posts have meant that I’ve been exercising and eating more healthily recently. Purchasing a blender has been a great idea from a healthy eating point of view; though the ingredients sound weird, green smoothies are awesome!
Not a green smoothie, but you get the idea!
The past few months have also been populated by not one, but two lip sync parties. The first was a full on competition (unfortunately, images and videos have been banned from the internet by mutual agreement), and though I didn’t make the top three, it was a good night.
Anyway, onto the some CS stuff 🙂 During a Computer Science degree, you learn a lot of stuff, but uni can’t teach you everything; and there’s always more to know. I thought of five things that aren’t typically included (or could be covered in more detail) in many courses. It’s not a comprehensive extra-curricular guide, I think all of these things are super interesting, and/or really useful, I hope you agree!
1. Data structures
Making a concious effort to expand your knowledge about data structures is a fantastic investment; they’re the butter to the algorithmic bread of CS. During the course of an undergrad, we hear about and use most of the basic data structures; arrays, linked lists, stacks, binary trees etc. Occasionally, we’ll need to implement one, maybe for a lab exercise or if we’re working in a low level language like C or Assembly.
I think it’s important to have a good awareness of more data structures than just ‘the basics’ though. Managing your data well can increase the speed of what you’re implementing, often drastically. For example, Dijkstra’s algorithm has a runtime of O(E log(V)) for a when its using a binary heap, but O(E + V log(V)) when using a Fibonacci heap, which is much better for graphs with a lot of edges. In fact, in the second year algorithms course at university, we implemented Dijkstra’s algorithm, and ran it on a fairly large graph. I remember significantly improving the run-time of the algorithm by representing the outlist of each node in the graph as an array instead of a linked list since arrays have a better cache coherency.
So, we’ve established that knowing what options are available and when they’re best applied is important, but being programmers, its also important that we implement them too. I suggest taking the time to implement a basic version of a data structure if you’re coming across it for the first time, so you can really get a feel for the trade offs and design decisions it has.
So, here’s a list of some cool ones in order of increasing complexity/obscurity:
A Trie is a data structure often used for efficiently storing strings of text. It uses memory very efficiently, and is often very useful in technical interviews! There’s a great introductory article with a Java implementation here.
Circular Buffers are just like regular buffers, except they wrap around when you reach the end of them. This is good, since it provides a hard limit on the size of the buffer, and means you don’t have to worry about managing the size of a backing array etc.
Unrolled Linked Lists are just like normal linked lists, except each node can store multiple items. This means you get O(1) insertion/deletion, but also improved cache coherency like an array.
A HAMT (Hash Array Mapped Trie), combines the idea of a Hash Table with that of a Trie. Its more versatile than a Trie, yet retains the memory efficiency. Here’s a nice blog post about them.
There are a class of data structures that are ‘cache-oblivious’. This means they are designed with the memory hierarchy of current CPU’s in mind (e.g. L1 cache, L2 Cache etc), and don’t assume that memory accesses all take constant time like most data structures do. Here’s an interesting read on the topic.
If you thought those were neat, maybe look up Finger Trees, Interval Trees, CHAMP and soft heaps. If this all seems easy, then maybe you could take a look at purely functional datastructures 🙂
2. Learn a functional language
Though I’ve never taken a module in my degree with a significant functional programming aspect (though there are ones available!), FP is gaining traction in industry and is great for giving a new, different perspective on programming.
However, not being explicitly taught something is no excuse for not learning it! There are loads of opportunities to use FP in university, for example, in the first year distributed systems course, you’re asked to build a simple web browser in Python. The aim is to parse a very simple HTML file and display it on the terminal. I parsed the input into a DOM-style structure and then rendered it on the screen, and did it all in a functional style (which made things a lot easier!).
Another great opportunity to use FP is in the AI and Games course in third year. For the labs there, you write an AI for Kalah, which essentially involves building a game tree and running minimax on it. However, since trees (by their nature) are recursive, you can code your solution much more elegantly using FP techniques than using an imperative/object oriented style (though we’ve implemented our solution in C for speed).
Functional Programming isn’t just about tail recursion, lambda expressions and a map function though. It’s a whole new paradigm with interesting trade offs, ideas, problems etc. A few years ago, I spent the Summer writing a REST service in Scala at Morgan Stanley, which was invaluable for helping me understand what FP really is.
3. Become competent on the command line
You’re probably already good on the command line, maybe you have a custom `.bashrc` file and use fancy arguments for `ls`, but are you using the terminal to its full potential? I certainly don’t!
If you’ve never looked into it, you may be surprised by just how much you can do from the command line, even after just learning a few new commands.
For example, you can use the `parallel’ command to utilize multiple cores on your machine. Lets say you wanted to convert all .jpg files in a directory to .png files using convert, you could use parallel to use all of the cores on your processor instead of just one.
Other cool tools to check out include xargs and pv (a progress bar). If you’ve not used different shells before, maybe try out something like fish, or maybe just read the man page for bash!
4. Learn about Computer Security
Computer security is something everybody interested in CS should have a basic knowledge of. Knowing what DDOS stands for and why it’s a good idea to have a firewall is a good idea for people who (may one day) write software for thousands if not millions of users.
Computer security isn’t all about cracking passwords, man in the middle attacks and Java vulnerabilities though. Social engineering is a common attack vector for hackers, I recommend Kevin Mitnick’s book The Art of Deception if you’re interested in this (occasionally available cheaply on Amazon).
5. Have a go at parallel and distributed computing
Writing single threaded code is something that most computer scientists get pretty good at. Making different computations happen at the same time either on the same machine, or on different machines adds a whole new level of complexity though.
There are lots of different approaches to parallelizing your code, from using the `parallel’ command as mentioned above, to writing map reduce jobs and running them on a cluster of virtual servers you’ve set up.
I recently read an interesting blog post (warning, it’s a long read) about how Erlang has separate modules that are designed to embrace crashing, and handle it gracefully and transparently. While I think that implementing a fault tolerant and distributed project in Erlang might be overkill, there are lots of university labs that are ripe for a bit of multi-threading!
I had planned to write a blog post at the start of January, but as usual exam time came around I was too busy! Thankfully, my exams have gone well (though I only had two!) and now I do have time to write again 🙂
Over exam time, interest in my course notes usually goes up as people start their revision. This year, both the first and second years were looking at them (as opposed to last year when there was only one year ‘younger’ than me at uni), which meant roughly double the attention! From the traffic to my website, it looks like Manchester students start revision at the start of January (new year new me mindset?):
While it’s fab people are using my notes, I wish they would contribute more too; I’m sure there are lots of mistakes in there, and while I regularly get feedback on them, they’re all open source for people to improve on (first year, second year, third year).
Of course, hosting a website used by procrastinating CS students has its risks. Each notes .pdf file has a separate link to download along a path such as:
todddavies.co.uk/notes/dl/Uni/COMP112.pdf
There was one time when somebody tried to have some fun with my server by attempting to download some sensitive stuff:
todddavies.co.uk/notes/dl/../../../etc/passwd
Thankfully, my server didn’t hand over the `/etc/password’ file since although it looks like my notes are stored on my server, they really just redirect to Github (so I can save on bandwidth). It was certainly a wake up call for me to harden by server though!
While thinking about updates to by website, I remembered a cool section on my friend Brandon Wang’s website, where he lists what he’s currently reading. I decided that incorporating a similar section into my site would be fun, and a good opportunity to try out microservices.
I set about developing LiteraryLog, a simple API written in Java that collates information from Goodreads and my reading lists to show what I’m reading at the moment. It’s nice and extensible so that I can add more feeds in the future (I think connecting it to my browser history and having it determine what articles I’ve recently read would be fun).
The idea is that LiteraryLog runs on a separate port to my normal website, and all that the website process (a Django application) has to do is grab the data and format it as a webpage. This way, the logic is nicely decoupled from the interface. While the Java app is pretty fully featured (despite a few small missing features and bugs), the front end is pretty basic as you can probably tell, but I can evolve it over time.
Outside of computer related things, I’ve been exploring Manchester’s Northern Quarter recently and have found even more super cool places than I realised were there. In particular, I visited Takk the other day which is a Nordic inspired coffee shop.
This month has (thankfully) been slightly less busy than the previous few of Third Year, though I’ve still been up to a lot in the Kilburn Building!
My third year project has been progressing nicely; I’ve now got a fully functional Part of Speech tagger that’s parallelised on CPU cores, and am starting to port it over to the GPU. I also did a seminar on how the project has progressed so far, the slides of which are online.
Since I’m planning on doing a Masters next year (either in Computer Science or Computational Biology), I’ve been looking at internships for the Summer in between graduating from my current degree, and starting my next. Things are progressing well for another internship at Google this Summer, some pretty cool projects are being banded about!
Outside of the course, I’ve been thinking quite a bit about what impact Computer Scientists are having on society. There’ve been a plethora of climate change related viewpoints posted on websites such as HackerNews, Lobste.rs, Twitter etc, probably prompted by the worldwide coverage of COP21.
Among these, was a rather large post (which I strongly encourage you to read) on what a technologist can do about climate change. It goes over all the different challenges that we (as a society/race) need to overcome in order to create a sustainable way of living (plus how technologists can help), and the use of data visualisations to back up the content is fantastic (a fantastic application of Javascript apart from anything!).
In the article, you can interact with the data on the right of the picture, and the values in the text on the left will automatically update, which helps you gain an intuitive understanding of the data. So cool!
I don’t think it was in the aforementioned article, but I recently read something along the lines of:
Worrying about game AI, packet routing, natural language processing etc when climate change is happening all around us, is akin to standing on some train tracks with a train coming and worrying about a lightning strike.
I think the quote is slightly too harsh; a professor working on NLP (natural language processing) can’t have much of a direct impact on something like decarbonization or green energy. However, I do think that more students should consider working on problems such as climate change (medicine, government etc too) before blithely letting themselves work on something that’s possibly technically interesting, but ultimately frivolous.
Even though my final year is really still just beginning, now’s the time that I have to make all the big decisions about what I’m going to do after I graduate; things take ages to organise!
The way I see it, final year CS students have two options. Either you carry on studying by pursue another degree such as a Masters or PhD, or you find a job and start your career. Both have their respective pros and cons, and it’s certainly a complicated decision.
I often think that when faced with a hard problem, the best solution is to avoid the problem in the first place. In this case, the solution is to apply for further higher education and jobs at the same time, and then do whatever the best option that I end up with 🙂
On the job front, I recently had on-site interviews with Palantir in New York. My long standing opinion that the best job interviews include an all expenses paid trip the NYC, was definitely vindicated in this case, since I got to stay in a super four star hotel for three nights, and see all the sights on the three days that I wasn’t interviewing!
The lobby of my hotel.
The actual interviews included four technical (whiteboard coding) interviews, and one semi technical system design/interpersonal interview. The questions were really fun, not your stereotypical ‘reverse a linked list’, or ‘traverse a tree in post-order’ stuff.
I also got the chance to meet up with a housemate from last year who is studying at New York University this year. He looks to be having a great time, and he was the perfect tour guide around the city.
The World Trade Centre, New Jersey and the Statue of Liberty.
The interview came at a good time, since it’s reading week and I don’t have any lectures to attend or labs to do. However, it’s put me quite far behind in terms of the third year project work I was hoping to get done (except from a few hours of distracted programming on the plane). At the moment, I’m working on implementing a Brill Tagger in C++, which isn’t too conceptually hard, but the devil is in the implementation detail, especially when a small issue such as a small memory leak can become an issue when you’re dealing with a data set of 100 million words. I guess I’ll have to put my nose to the grindstone this weekend!
As I said before, I’m also looking at doing a postgraduate degree. See, I don’t feel as though my computer science education is complete (despite the best efforts of the faculty at Manchester). Three years is simply not enough time to learn everything, and I really want to continue my education a bit more before I decide to get a job, after which I think it’s harder (but not impossible) to learn new things. As a consequence, a masters degree seems like a good option for me.
I can apply the advice I was given when selecting my current CS degree to now, when I’m selecting a masters. You need to think about whether you like the university, the city that the university is in, and the degree itself. For universities, I’m looking at Cambridge, Imperial College London, Edinburgh, ETH Zurich and (of course) Manchester. Zurich is the cheapest in terms of course fees, but also comes with lots of complications, such as living costs (Zurich is crazily expensive) and language barriers. I really like the look of the Advanced Computing course at Imperial College London, but it’s also the most expensive of my choices.
Obviously, choosing the actual course is another decision. Basically, my options at the moment are some kind of ‘Advanced CS’ course, or some kind of ‘Computational Biology’ course. Advanced CS will be similar to what I’m doing now, just at a higher level and more in depth, whereas Computational Biology will expose me to whole new areas of study, and potentially open up a lot of new opportunities, while being lighter on the CS side.
I suspect that I’ll end up sending quite a few masters applications off so that I have all my bases covered.
A busy street!
In terms of ‘normal’ uni work (excluding interviews, postgrad applications and project work), I’m looking forward to the next half of the semester. Stuff on the cards includes code reviewing the implementation of Tarjan’s Strongly Connected Graph algorithm we wrote for Advanced Algorithms 1 and implementing an AI for Kalah in the AI and Games course, both of which should be really fun.
I suppose that since this is my first post, I should write a little bit about myself; I’m twenty years old, in my third (and final) year of a Computer Science degree at the University of Manchester, and I’m passionate about sport (specifically karate and bouldering at the moment) and being a software engineer.
I’ve been out of the country for the past four months while I was doing a Summer Internship at Google Munich, so it’s great to be back in Manchester; especially since I get to see all of my friends again.
I guess since I’ve only been in Manchester for a total of four days now, there’s not too much to write about in that regard, but lots of cool stuff happened in Germany, so you can hear about that instead.
I’ve wanted to become a ‘Googler’ for a long time now, so when I heard that I had been offered an internship over the summer, I was super excited! When you apply for an internship at Google, you have to apply to a specific region (this was EMEA – Europe, Middle East and Africa, for me), and you can be hired into any office in that region. London is a large engineering office for Google, and being based in the UK, I assumed I’d be matched with a team there. I was certainly surprised when I got a call asking if I’d like to intern in Munich!
Marienplatz, seen from the tower of St Peter’s Church, 200 meters from the office.
I figured that despite speaking practically no German, and having never lived abroad, working in Deutschland for a Summer would be too good of an opportunity to miss. I was told that the project I was working on was secret, and I’d be programming in Java, which also sounded good to me.
Finding accommodation in Munich is really hard, it’s a very desirable place to live, and house prices are sky-rocketing. Thankfully, after only around half an hour of searching, I found a landlady on a website for English speakers living in Germany who was willing to let me rent.
The house turned out to be twenty minutes on the U-bahn (the subway) from the centre of Munich (which is where the Google office is). It was also really near the Isar, which is the river running through Munich; perfect for running/cycling down, or just relaxing with a beer!
The pinnacle of my burgeoning latte art career at Google.
There were about twenty other interns in the Munich office, which is maybe around one intern per team. The Google website describes the Munich office as having ‘more than the number of known moons in our solar system’ Googlers in it, but I disagree, there are probably around ‘the number of possible states of a nine bit binary number’ 😉
My project was really cool. I was in a team working on Google accounts and their associated infrastructure, and I got to work with lots of the tech that Google is most famous for, including running Map Reduce jobs on many, many machines, using Spanner (a super cool database), and much more stuff that’s still internal. Perhaps the best bit for me was working every day with people who are quite possibly the best software engineers I’ve ever met, having them review my code, show me best practices, and just having a blast with them!
Amongst my team, bouldering was a favoured activity outside of work. Twice a week, five of us would head down to Boulderwelt before work to spend a few hours there. Bouldering is like climbing, except you never go above ~4 meters, and there are very thick mats below you so it’s kind of safe(ish) to fall off at any point. One reason it’s popular within the office, is that it’s really good at relieving lower back pain from sitting at a desk for too long, which is a problem that lots of software engineers have to deal with.
I think there’s far too much cool stuff that happened in my internship to properly give justice to in a single blog post. Working there was beyond amazing, it’s such a shame I had to leave! However, coming back to university is always super fun too, and I’m sure third year will keep me very well occupied!
Chrome’s seventh birthday cake was by far the best birthday cake I’ve ever seen (and eaten)!
I plan on updating this blog once a month or so, stay tuned!






![DRU3443-1500x700[1]](http://www.mub.eps.manchester.ac.uk/todd-davies/wp-content/uploads/sites/46/2016/01/DRU3443-1500x7001.jpg)







